环境搭建
CMD
- nvcc -V
- nvcc –version
架构
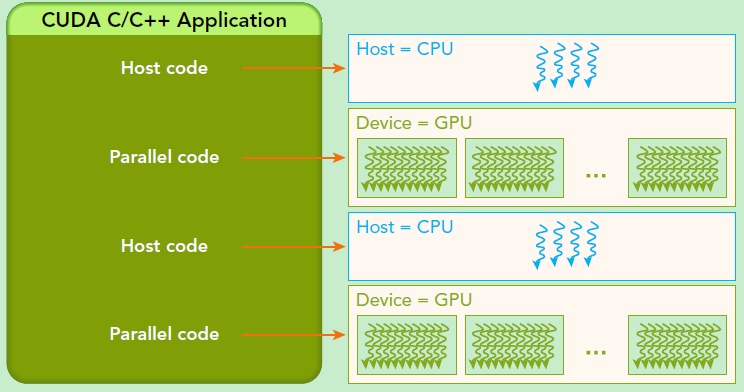
- host: 指代CPU及其内存
- device:指代GPU及其内存
典型的CUDA程序的执行流程如下:
- 分配host内存,并进行数据初始化;
- 分配device内存,并从host将数据拷贝到device上;
- 调用CUDA的核函数在device上完成指定的运算;
- 将device上的运算结果拷贝到host上;
- 释放device和host上分配的内存。
由于GPU实际上是异构模型,所以需要区分host和device上的代码,在CUDA中是通过函数类型限定词开区别host和device上的函数,主要的三个函数类型限定词如下:
- global:在device上执行,从host中调用(一些特定的GPU也可以从device上调用),返回类型必须是void,不支持可变参数参数,不能成为类成员函数。注意用__global__定义的kernel是异步的,这意味着host不会等待kernel执行完就执行下一步。
- device:在device上执行,单仅可以从device中调用,不可以和__global__同时用。
- host:在host上执行,仅可以从host上调用,一般省略不写,不可以和__global__同时用,但可和__device__,此时函数会在device和host都编译。
FEATURED TAGS
jekyll
RubyGems
Blog
Mac
终端
Git
弹塑性分析
非线性
SAUSAGE
Github
纤维素
分层壳
iOS
ABAQUS
Avg:75%
魔方
三阶
二阶
广东实验公开赛
WCA
SAP2000
Williams双杆体系
几何非线性
GitBook
Markdown
Typora
Node.js
html
超限
抗剪截面验算
剪压比
微信公众号
地震波
波谱分析
动力弹塑性分析
初始缺陷
欧拉公式
动力弹塑性
超高层
选波
视频
Delta
SAUSG
屈曲分析
弹塑性时程分析
子程序
跨层柱
层间位移角
层剪力
HKSC
steel
Eurocodes
弹塑性
非线性设计
AISC
Imperfections
YJK
直接分析法
delta
构件缺陷
整体缺陷
直接分析设计
SAUSG-Delta
原理
案例
PPT
建筑云联盟
C++
MFC
ChartCtrl
fema
pushover
Equivalent Linearization
RGB
编程
颜色
网络
远程桌面
PI
ZETA
DELTA
OpenSAUSG
VS
C
CUDA
fwrite
二进制
bat
cmd
rdp
mstsc
数据结构
2024
深度学习
cuda
miniconda
pytorch
ChatGPT